This notebook describes how to build a deep learning classifier that can classify cell status from papsmear images using a transfer learning approach.
Introduction
Project outline
We will create and train a deep learning classifier using a transfer learning approach. First we will establish a base classifier model using pretrained weights and network architecture from the Xception model [Chollet, 2017]. To further fine-tune this base classifier, we will add a new top layer to the Xception model, which we subsequently will train on the SIPakMed data set [Plissiti et al., 2018] while freezing the original weights in the other layers of the Xception model. Additionally, we will perform hyper parameter tuning to find the best hyperparameters for the top layer. After finding a model with optimal hyperparameters, we will fine-tune the network further by unfreezing the pretrained weights in the Xception layer. We will use a very small learning rate when fine-tuning the model to avoid overfitting.
The SIPaKMeD data set
The SIPaKMeD data sethttps://www.cs.uoi.gr/~marina/sipakmed.html consists of 4049 images of isolated cells that have been manually cropped from 966 cluster cell images of Pap smear slides. These images were acquired through a CCD camera adapted to an optical microscope. The cell images are divided into five categories containing normal, abnormal and benign cells (descriptions taken from the SIPaKMeD website ):
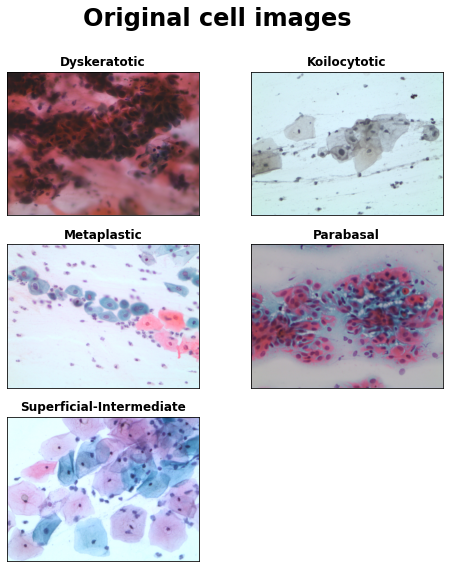
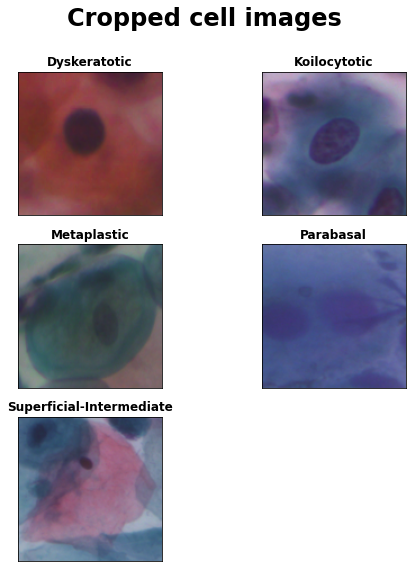
Superficial-Intermediate cells constitute the majority of the cells found in a Pap test. Usually they are flat with round, oval or polygonal shape cytoplasm stains mostly eosinophilic or cyanophilic. They contain a central pycnotic nucleus. They have well defined, large polygonal cytoplasm and easily recognized nuclear limits (small pycnotic in the superficial and vesicular nuclei in intermediate cells). These type of cells show the characteristics morphological changes (koilocytic atypia) due to more severe lessions.
Parabasal cells are immature squamous cells and they are the smallest epithelial cells seen on a typical vaginal smear. The cytoplasm is generally cyanophilic and they usually contain a large vesicular nucleus. It must be noted that parabasal cells have similar morphological characteristic with the cells identified as metaplastic cells and it is difficult to be distinguished from them.
Koilocytotic cells correspond most commonly in mature squamous cells (intermediate and superficial) and some times in metaplastic type koilocytotic cells. They appear most often cyanophilic, very lightly stained and they are characterized by a large perinuclear cavity. The periphery of the cytoplasm is very dense stained. The nuclei of koilocytes are usually enlarged, eccentrically located, hyperchromatic and exhibit irregularity of the nuclear membrane contour.
Dysketarotic cells are squamous cells which undergone premature abnormal keratinization within individual cells or more often in three-dimensional clusters. They exhibit a brilliant orangeophilic cytoplasm. They are characterized by the presence of vesicular nuclei, identical to the nuclei of koilcytotic cells. In many cases there are binucleated and/or multinucleated cells.
Metaplastic Cells are in essence small or large parabasal-type cells with prominent cellular borders, often exhibiting eccentric nuclei and sometimes containing a large intracellular vacuole. The staining in the center portion is usually light brown and it often differs from that in the marginal portion. Also, there is essentially a darker-stained cytoplasm and they exhibit great uniformity of size and shape compared to the parabasal cells, as their characteristic is the well defined, almost round shape of cytoplasm.
Library imports
code
import numpy as npimport pandas as pdimport tensorflow as tfimport matplotlib.pyplot as pltimport cv2import glob, osfrom PIL import Imagefrom tensorflow import kerasfrom sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay%matplotlib inline
code
%pip install -q -U keras-tuner
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 135.7/135.7 KB 5.2 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.6/1.6 MB 10.7 MB/s eta 0:00:00
code
import keras_tuner as kt
Data visualization
In order to better understand the data set, we will retrieve and visualize a few images before building the model. Additionally, we will check whether the data set is balanced with regards to the class labels.
Retrieve images
Fist we will set the correct file system locations to retrieve all images from Google drive.
Let’s start with visualizing the original images. The original images were taken from papsmear images and are still unsegmented, containing multiple cell types still per image.
The data set also contains cropped images, which only contain single cells that were extracted after image segmentation. We will use those cropped cell images for training the deep learning classifier.
It is important to check whether the data set is balanced with regards to the various cell categories. We will use the labels to train the classifier with, so it is important that those are balanced. We will inspect class balance by counting the class labels per cell type in the data set and assessing that all classes have similar proportions in the data set.
code
file_dict = {}for c in CLASSES: file_dict[c] = glob.glob(os.path.join(IMAGGE_DIR, c, '*bmp'))total_nr =sum([len(file_dict[x]) for x in file_dict.keys()])print(f"Total nr of images found: {total_nr}")for k,v in file_dict.items(): nr_per_class =len(file_dict[k])print(f"Class '{k}': {nr_per_class} ({(nr_per_class *100// total_nr):.2f}%) images found")
Total nr of images found: 966
Class 'Dyskeratotic': 223 (23.00%) images found
Class 'Koilocytotic': 238 (24.00%) images found
Class 'Metaplastic': 271 (28.00%) images found
Class 'Parabasal': 108 (11.00%) images found
Class 'Superficial-Intermediate': 126 (13.00%) images found
code
file_cropped_dict = {}for c in CLASSES: file_cropped_dict[c] = glob.glob(os.path.join( CROPPED_DIR, c, '*bmp'))total_cropped_nr =sum([len(file_cropped_dict[x]) for x in file_cropped_dict.keys()])print(f"Total nr of cropped images found: {total_cropped_nr}")for k,v in file_cropped_dict.items(): nr_per_class =len(file_cropped_dict[k])print(f"Class '{k}': {nr_per_class} ({(nr_per_class *100// total_cropped_nr):.2f}%) cropped images found")
Total nr of cropped images found: 4049
Class 'Dyskeratotic': 813 (20.00%) cropped images found
Class 'Koilocytotic': 825 (20.00%) cropped images found
Class 'Metaplastic': 793 (19.00%) cropped images found
Class 'Parabasal': 787 (19.00%) cropped images found
Class 'Superficial-Intermediate': 831 (20.00%) cropped images found
We can see that the classes are fairly balanced in the cropped images. Since we will use only those cropped images for training the model, no further adjustments with regards to class balance need to be made.
Data set loading
After visual inspection of assessment of class balance, we will import the data set with cropped images for futher analysis. Keras provides some utilities to load the data set directly from a hierarchical directory, where each cell category is placed in a separate subfolder.
Furthermore, we will split the data set into a training, validation and test set. We will use the training and validation sets for fitting model weights and tuning hyperparameters, while the test set will only be used for evaluating model performance of the trained network.
Found 4049 files belonging to 5 classes.
Using 3240 files for training.
Found 4049 files belonging to 5 classes.
Using 809 files for validation.
code
class_names = train_ds.class_namesprint("Class names found in training data set:")for i,n inenumerate(class_names):print(f"{i}. {n}")
Class names found in training data set:
0. Dyskeratotic
1. Koilocytotic
2. Metaplastic
3. Parabasal
4. Superficial-Intermediate
code
val_batches = tf.data.experimental.cardinality(validation_ds)test_ds = validation_ds.take(val_batches //5)validation_ds = validation_ds.skip(val_batches //5)print('Number of train batches: %d'% tf.data.experimental.cardinality(train_ds))print('Number of validation batches: %d'% tf.data.experimental.cardinality(validation_ds))print('Number of test batches: %d'% tf.data.experimental.cardinality(test_ds))
Number of train batches: 102
Number of validation batches: 21
Number of test batches: 5
Data preprocessing
Before we can feed the data into the nearal network, we still need to perform some preprocessing. Firstly, we will create an augmentation layer that will apply some transformations on the original images to generate additional training images. Afterwards, all images still need to be further standardized and scaled before feeding them into the neural network, so we will also add a standardization layer
Performance optimization
To optimize performance of the data preprocessing pipeline, Tensorflow provides a software pipelining mechanism through the tf.data.Dataset.prefetch transformation that will use a background thread to prefetch elements from the input data set ahead of the time they are requested. So during data preprocessing, this utitlity will prefetch and offload data loading, augmentation and scaling to a background thread, which will improve performance.
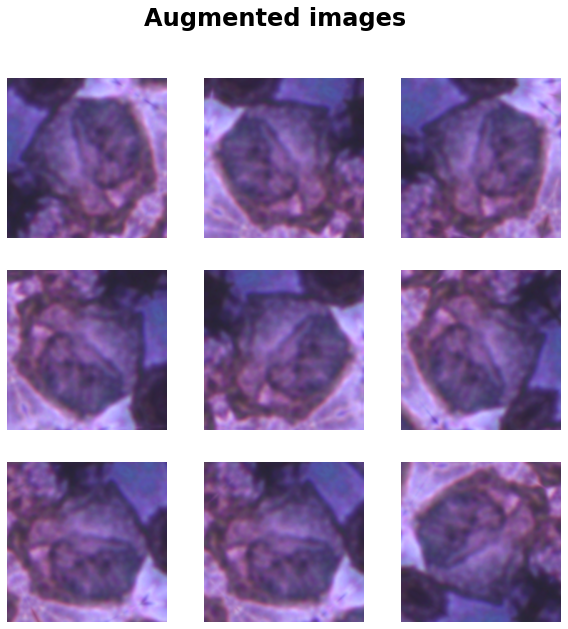
To increase the nummer of images available for training the model, we will create a data augmentation layer. This data augmentation layer will generate extra training images by flipping and randomly rotating the original training images.
Importantly, note that we will not apply any color-changing transformations during this data augmentation step, because the colors in the images are induced by cell staining and convey crucial information about cell status.
for image, _ in train_ds.take(1): plt.figure(figsize=(10, 10)) plt.suptitle("Augmented images", fontsize=24, fontweight='bold') first_image = image[0]for i inrange(9): ax = plt.subplot(3, 3, i +1) augmented_image = data_augmentation(tf.expand_dims(first_image, 0)) plt.imshow(augmented_image[0] /255) plt.axis('off')
Create preprocessing layer
Additionally, we will create a preprocessing layer that will standardize and scale all values of an image array between [-1, 1] before feeding the output into the Xception layers. This functionality is provided by the method preprocess_input in the mobilenet_v2 module.
To create a base model, we will download the Xcption model via the Keras API using keras.applications.Xception. Note that we can specify to download pretrained weights by setting parameter weights='imagenet'. Those weights were obtained by training the Xception network on the imagenet data set [Deng et al., 2018]. We will then perform transfer learning by initializing the network with those pretained Xception weights trained om Imagenet and then to repurpose the network for a new classification task. To preserve the pretrained weights and to make sure they are not overwritten during training of the new classiication layer, we set parameter base_model.trainable=False.
When we set parameter include_top=False, the final classification layer of the Xception network is not included in the network architecture. So we will add a new, final classification layer ourselves to the headless Xception network and train this output layer on the SIPaKMeD data set.
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/xception/xception_weights_tf_dim_ordering_tf_kernels_notop.h5
83683744/83683744 [==============================] - 0s 0us/step
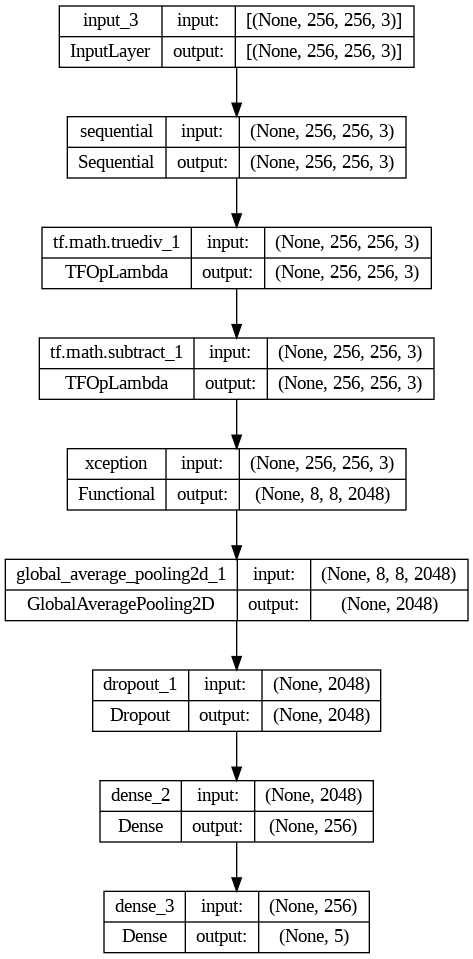
We can test whether the network architecture works by providing an input batch containing images of 256 by 256 with 3 color channels (e.g. also see the input parameter input_shape=(256,256,3) to the Xception base model. The network will then return a feature vector of shape (32, 8, 8, 2048). The first dimension denotes the batch size, whereas the remaining (8.8.2048) dimension is the result of applying various convolution operations by the Xception network architecture. So we will still need to add a new classification to the headless Xception network that will use this feature vector to classify the cervical cell types.
We can extend the headless Xception network architecture using the Keras functional API.
We will add he preprocessing and data augmentation layers as follows:
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
After we have added the base model layers and before the next Dense layer, we will add a Dropout layer for regularization and to avoid overfitting. Note that we have specified several dropout rates. Those will get tested automatically during hyperparameter optimization.
hp_dropout_rate = hp.Choice('dropout_rate', values=[0.2, 0.3] )
x = tf.keras.layers.Dropout(rate=hp_dropout_rate)(x)
After we have added the Dropout layer, we will add a Dense hidden layer, which will flatten the (32, 8, 8, 2048) dimensional tensor to a feature vector which subsequently will be used by the final layer for classification. Similar to the Dropout layer, we have specified several values for the number of hidden units, which will automatically get tested during hyperparameter optimization. This hidden Dense layer has a relu activation function.
hp_units = hp.Int('units', min_value=128, max_value=256, step=64)
x = tf.keras.layers.Dense(units=hp_units, activation='relu')(x)
After we have added all preprocessing and internal layers, will add the final output layer that will perform the predictions. This output layer has 5 unit because there are 5 cell categories that it will predict. As an activation function, we will use a softmax function, which will output a vector of length 5 containing probabilities for each cell category.
Besides adding some extra layers, we will also add ADAM [Kingma & Ba, 2014] as the stochastic optimization algorithm that will be used to learn the weights of the new network during training.
def model_builder(hp): inputs = tf.keras.Input(shape=(256, 256, 3)) x = data_augmentation(inputs) x = preprocess_input(x) x = base_model(x, training=False) x = tf.keras.layers.GlobalAveragePooling2D()(x) hp_dropout_rate = hp.Choice('dropout_rate', values=[0.2, 0.3] ) x = tf.keras.layers.Dropout(rate=hp_dropout_rate)(x) hp_units = hp.Int('units', min_value=128, max_value=256, step=64) x = tf.keras.layers.Dense(units=hp_units, activation='relu')(x) predictions = tf.keras.layers.Dense(5, activation='softmax')(x) model = tf.keras.models.Model(inputs=inputs, outputs=predictions) opt = keras.optimizers.Adam(learning_rate=0.001) model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=metrics)return model
Hyperparameter search
We will use KerasTuner [Malley, 2019] to find the optional dropout rate for the dropout layer and the optimal number of nodes for the hidden, dense layer. To find these parameters, KerasTuner will perform a hyperparameter search using the Hyperband algorithm [Li at al, 2017].
To reduce training time, we will define a Keras callback that will stop the training once the validation loss does not decrease after 3 epochs. The callback will also store the weights of the best model.
The following code will peform the hyperparameter search and return the best dropout rate and number of hidden nodes.
code
tf.get_logger().setLevel('ERROR')tuner.search(train_ds, validation_data=validation_ds, epochs=KT_NR_EPOCHS, callbacks=[early_stop])best_hps=tuner.get_best_hyperparameters(num_trials=1)[0]print(f"""Hypersearch finished.\nBest dropout rate: {best_hps.get('dropout_rate')}.Best nr of units: {best_hps.get('units')}""")
Hypersearch finished.
Best dropout rate: 0.3.
Best nr of units: 256
Model fitting
After the best drouput rate and number of hidden units for the hidden layer have been found by the hyperparameter search, we can retrieve the best network model, initialized with those best parameters. We will then use this best network for further model fitting during the training phase.
Train top layer base model
We can retrive the best model as identified during the hyperparameter search as follows:
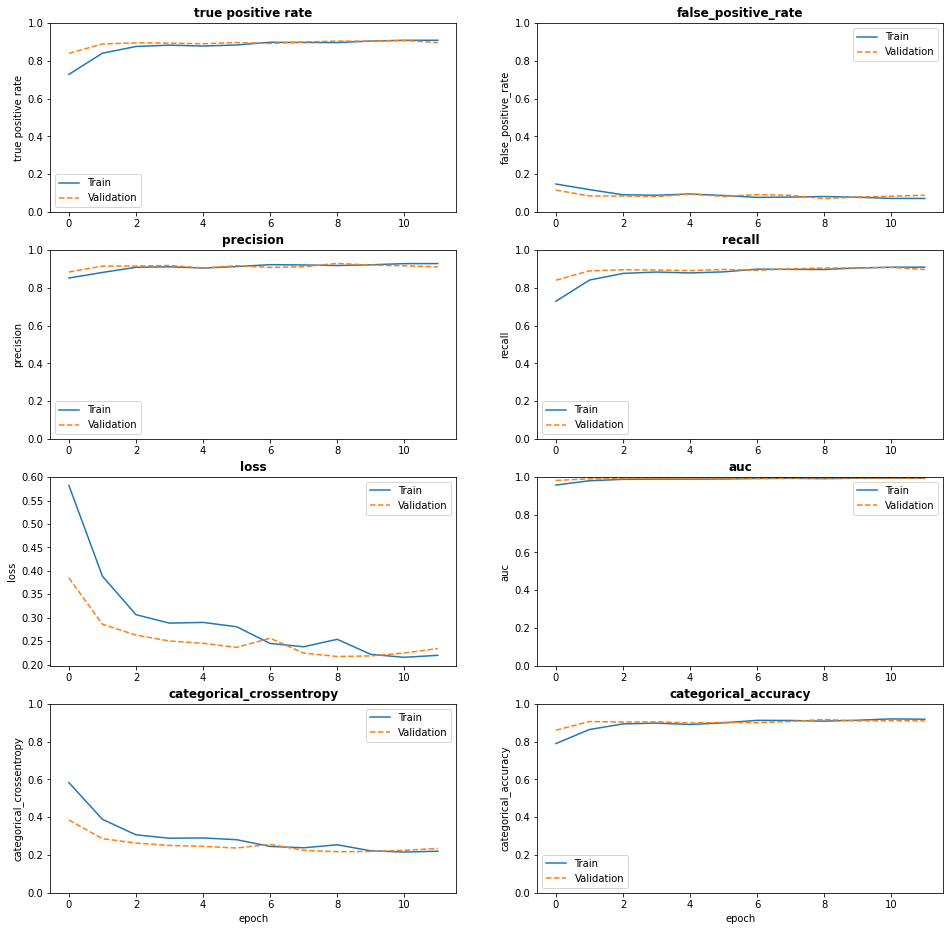
The following graphs provide some visualization of the metrics defined earlier during the training process. We can observe that the loss indeed goes down in the training and test set.
The best classifier was fitted in epoch 9 with the following performance metrics calculated on the validation set:
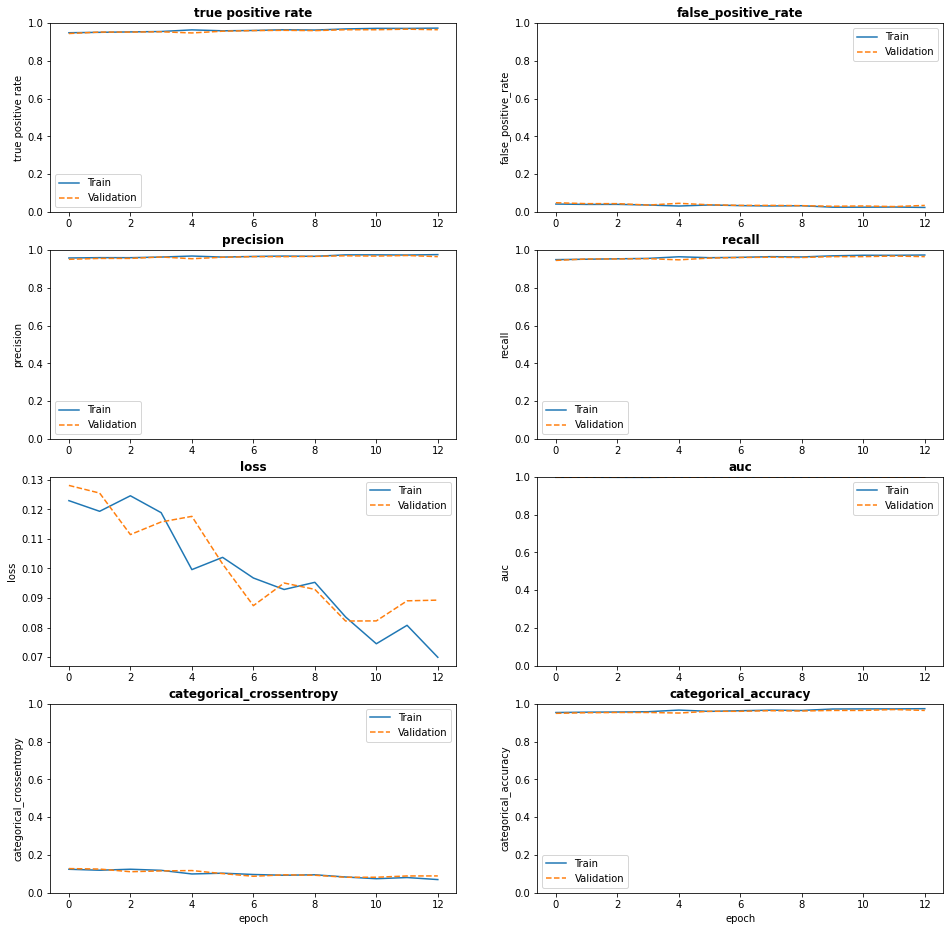
To further improve model performance, we can fine-tune the previous model. In order to perform fine-tuning of the network, we will freeze the Xception layers and then retrain all layers of the previous model. Importanly, we will use a very small learning rate (1e-4) to prevent overfitting.
We can persist the trained, best network model, by defining a Keras callback that will checkpoint the model and store the best weights with the lowest validation loss.
To get an unbiased estimate of actual model performance, we will evaluate the final model on the test data set to asssess how well the final model performs on previously unseen data. The test data set was held out during model training and not presented to the model before.
Model evaluation
We can obtain performance metrics for the final model on the test data set as follows:
code
print("Evaluate model on test data")test_results = best_model.evaluate(test_ds, batch_size=BATCH_SIZE)test_metrics = ("loss", "fn", "fp", "tn", "tp", "precision", "recall", "auc", "prc","categorical_accuracy", "categorical_crossentropy")print("\n\nPerformance final model on test data:\n")test_dict = {test_metrics[i]: test_results[i] for i inrange(len(test_metrics))}for k,v in test_dict.items():print(k,":",v)
Evaluate model on test data
5/5 [==============================] - 1s 175ms/step - loss: 0.1548 - fn: 9.0000 - fp: 9.0000 - tn: 631.0000 - tp: 151.0000 - precision: 0.9438 - recall: 0.9438 - auc: 0.9950 - prc: 0.9895 - categorical_accuracy: 0.9438 - categorical_crossentropy: 0.1548
Performance final model on test data:
loss : 0.15478989481925964
fn : 9.0
fp : 9.0
tn : 631.0
tp : 151.0
precision : 0.9437500238418579
recall : 0.9437500238418579
auc : 0.9949658513069153
prc : 0.9894886016845703
categorical_accuracy : 0.9437500238418579
categorical_crossentropy : 0.15478989481925964
The computed metrics for the test data set are actually slightly better than the training set, so the model seems to generalize well.
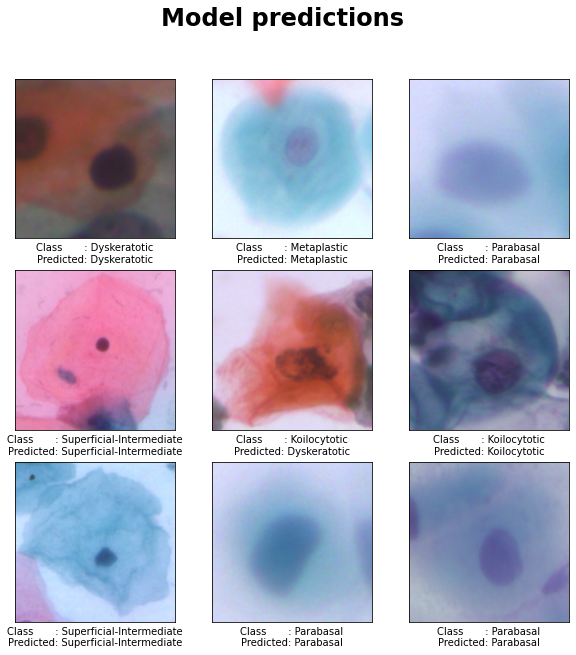
Model predictions
We can use the final model to predict class labels for individual images in the test data set and compare those predicted labels with the actual test labels as follows:
code
y_test = [np.argmax(y, axis=1).tolist() for _, y in test_ds]y_test = [class_names[item] for sublist in y_test for item in sublist]y_pred = np.argmax(best_model.predict(test_ds), axis=1).tolist()y_pred = [class_names[x] for x in y_pred]
From the plot with model predictions we can observe that the model correctly predicts 8 from the 9 selected images. The only incorrectly predicted class is for the middle image, where a Kolcytotic cell is incorrectly classified as a Dyskeratotic cell.
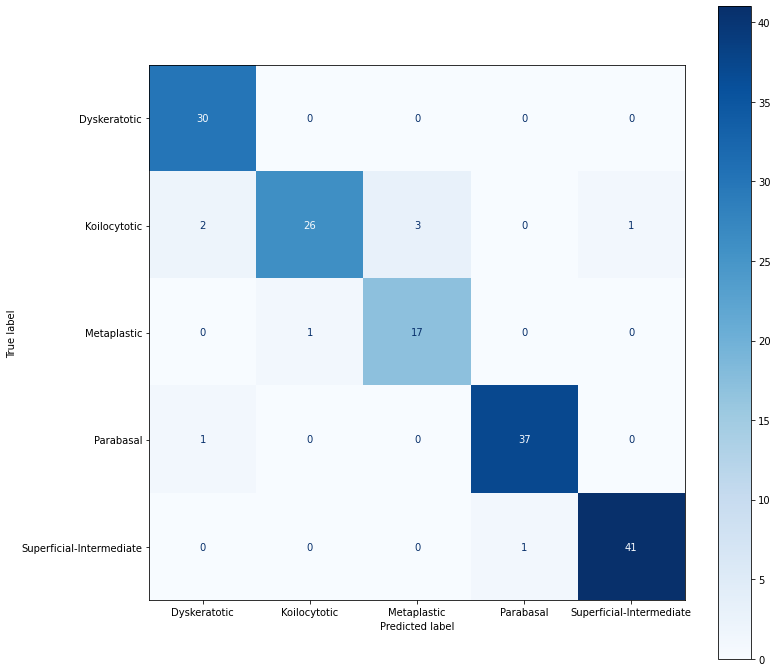
We can obtain a more comprehensive view of classifier performance by generating the confusion matrix for all 5 classes.
We can observe from the confusion matrix that most samples are correctly classified (i.e. high counts for the true positives in the diagonal, and several entries containing zeros in the other cells).
Furthermore, we can observe that most incorrect classifcations are for Kolocytotic cells, so to further improve performance of the classifier we could train the network with more Kolocytotic cell images.
Finally, let’s save the analysis to an HTML report.
code
!jupyter nbconvert --to html cervical_cancer.ipynb
[NbConvertApp] Converting notebook cervical_cancer.ipynb to html
[NbConvertApp] Writing 2244282 bytes to cervical_cancer.html
References
Chollet, F (2017). Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1251-1258).
Deng, J., Dong, W., Socher, R., Li, L. J., Li, K., & Fei-Fei, L. (2009, June). Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition (pp. 248-255). Ieee.
Kingma, D. P., & Ba, J (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
Li, L., Jamieson, K., DeSalvo, G., Rostamizadeh, A., & Talwalkar, A. (2017). Hyperband: A novel bandit-based approach to hyperparameter optimization. The Journal of Machine Learning Research, 18(1), 6765-6816.
Plissiti, M. E., Dimitrakopoulos, P., Sfikas, G., Nikou, C., Krikoni, O., & Charchanti, A. (2018, October). SIPAKMED: A new dataset for feature and image based classification of normal and pathological cervical cells in Pap smear images. In 2018 25th IEEE International Conference on Image Processing (ICIP) (pp. 3144-3148). IEEE. https://www.cs.uoi.gr/~marina/sipakmed.html