This projct demonstrates how to build a ranking model that can be used to score and rank recipes for a food recipe recommender system.
Introduction
In this analysis we will build a food recipe ranking model that can be used in recommender systems. We will build a user-item recommender system that can recommend recipes to users based on previous interactions. We will perform collaborative filtering with explicit feedback by using the recipes ratings as explicit user feedback. So given a user input ID, the system will return a list of ranked recipes IDs that might be of interest to that user based on that user’s rated recipes.
Recommender systems used in production typically consist of two phases:
The retrieval stage plays a crucial role in picking an initial set of several hundred candidates out of a vast pool of options. Its primary aim is to swiftly eliminate all candidates that fail to pique the user’s interest. Given that the retrieval model might need to sift through millions of candidates, it must be computationally efficient.
The next stage is the ranking stage, which further fine-tunes the outputs from the retrieval model to identify the optimal few recommendations. It will further narrow down the list of candidates retrieved during the retrieval stage and create a (ranked) shortlist of candidates.
In this analysis we will focus on building a ranking model that can used for ranking a list of candidates generated during the retrieval stage.
Load data
code
import osimport pprintimport reimport sysfrom ast import literal_evalfrom typing import Dict, Textimport matplotlib.pyplot as pltimport numpy as npimport pandas as pdimport seaborn as snsimport tensorflow as tfimport tensorflow_recommenders as tfrs
code
NROWS=10000BATCH_SIZE=128
Load rating data
We will start the analysis by loading the interaction data and extracting the user_id, recipe_id and rating. For this proof-of-concept analysis we will only import the first 10000 entries for speeding up training iterations.
For training and evaluating the ranking model we need to create a training and test data set. We will randomly shuffle the rating data and divide it into a training and test dataset using a 80/20 split.
Before building the user and item models, we will get all unique user and recipe IDs, which will be used as fixed vocabularies for the StringLookup layer and are also necessary to determine the dimension of the subsequent Embedding layer. Now that we have the vocabulary sizes to create the user and item embeddings, we can proceed to building the ranking model.
code
unique_recipe_ids = np.unique(list(x['recipe_id'] for x in ratings.take(NROWS).as_numpy_iterator()))unique_user_ids = np.unique(list(x['user_id'] for x in ratings.take(NROWS).as_numpy_iterator()))
Because a ranking model typically runs on fewer input candidates, the ranking model is not as computationally expensive as the retrieval model. We can therfore use a deeper model architecture. The ranking model architecture we will define consists of the user and item embedding layers, which are concatenated and feed into the ranking model, which is an multi-layer perception with a two densely connected layers. We will also add dropout to both dense layers to perform model regularization and to reduce the risk of overfitting.
So the model will take user and recipe IDs as inputs, which will get embedded into feature vectors by the user amd item model layers. Those feature vecutors will subsequenlty get concatenated and passed into the rating model, which will output a single score, which is the predicted user rating for a specific user ID and recipe ID.
code
class RankingModel(tf.keras.Model):def__init__(self):super().__init__() embedding_dimension =32# Compute embeddings for usersself.user_embeddings = tf.keras.Sequential( [ tf.keras.layers.StringLookup( vocabulary=unique_user_ids, mask_token=None ), tf.keras.layers.Embedding(len(unique_user_ids) +1, embedding_dimension, ), ] )# Compute embeddings for recipesself.item_embeddings = tf.keras.Sequential( [ tf.keras.layers.StringLookup( vocabulary=unique_recipe_ids, mask_token=None ), tf.keras.layers.Embedding(len(unique_recipe_ids) +1, embedding_dimension, ), ] )# Compute rating predictionsself.ratings = tf.keras.Sequential( [# Pass ratings through a multilayer perceptron tf.keras.layers.Dense(256, activation="relu"), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(64, activation="relu"), tf.keras.layers.Dropout(0.2),# Final outpt layer that will make the prdictions tf.keras.layers.Dense(1), ] )def call(self, inputs): user_id, recipe_id = inputs user_embedding =self.user_embeddings(user_id) recipe_embedding =self.item_embeddings(recipe_id)returnself.ratings(tf.concat([user_embedding, recipe_embedding], axis=1))
Once we have built the ranking model we can define the FoodRecipeModel, which is a tfrs.models.Model that combines the network model with a retrieval task. The retrieval task computes the loss and RMSE during traing. The FoodRecipeModel will take care of the training loop.
WE define a Keras callback that monitors the RMSE during training and will stop training if the RMSE does not improve during three consecutive training epochs. We also specify to return the best model weights in case of early stopping by setting restore_best_weigghts=true.
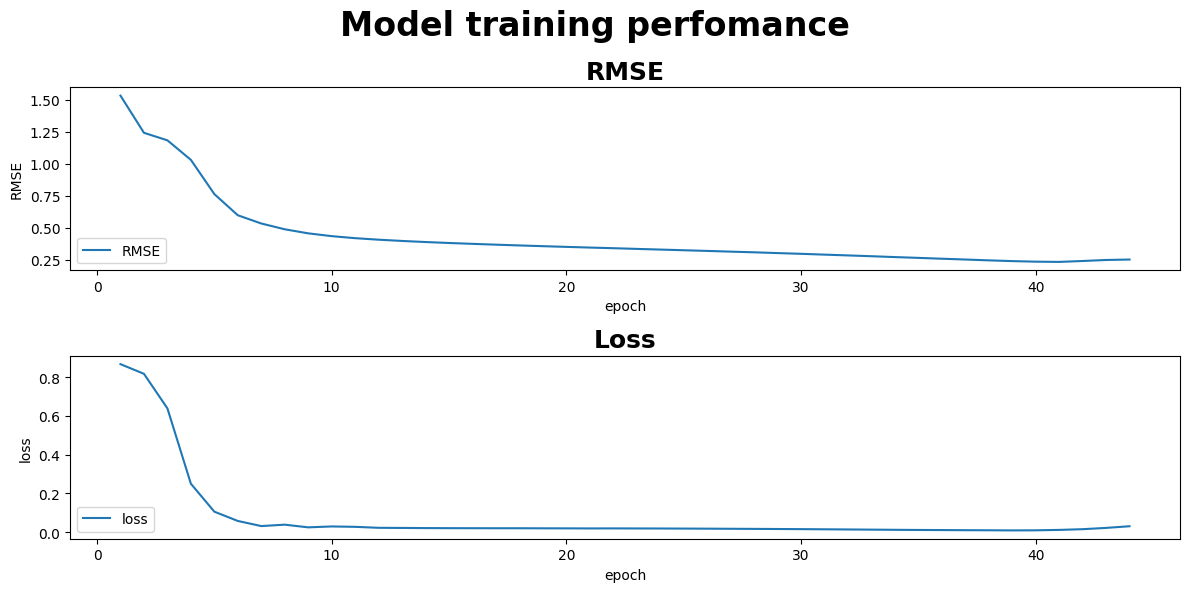
We can visualize the training loss and RMSE during training. We can observe that both training loss and RMSE are decreasing, indicating that the model performance is improving.
We can observe that the ranking model performs worse on the test set compared to the training set. The model might be overfitting because it is memorizing data that is has seen. Models with many parameters are prone to overfitting. We could mediate this by increasing the regularization in the embedding layers in the user and item models. We could also increase the Dropout rate in the Dense layers of the ranking model.
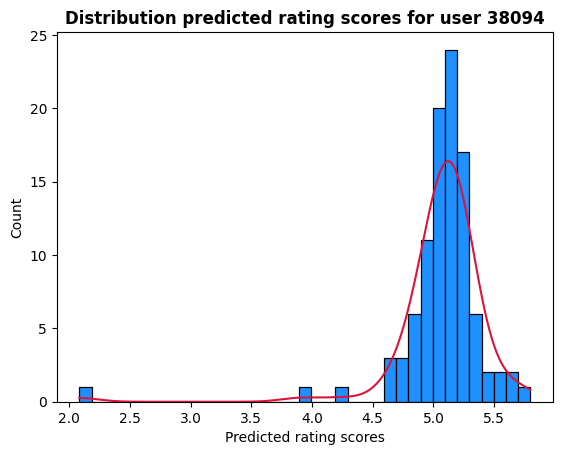
We can also inspect the distribution of the predicted ratings for out test user. We can observer that the scores follow a normal distribution with mean rating around 5.
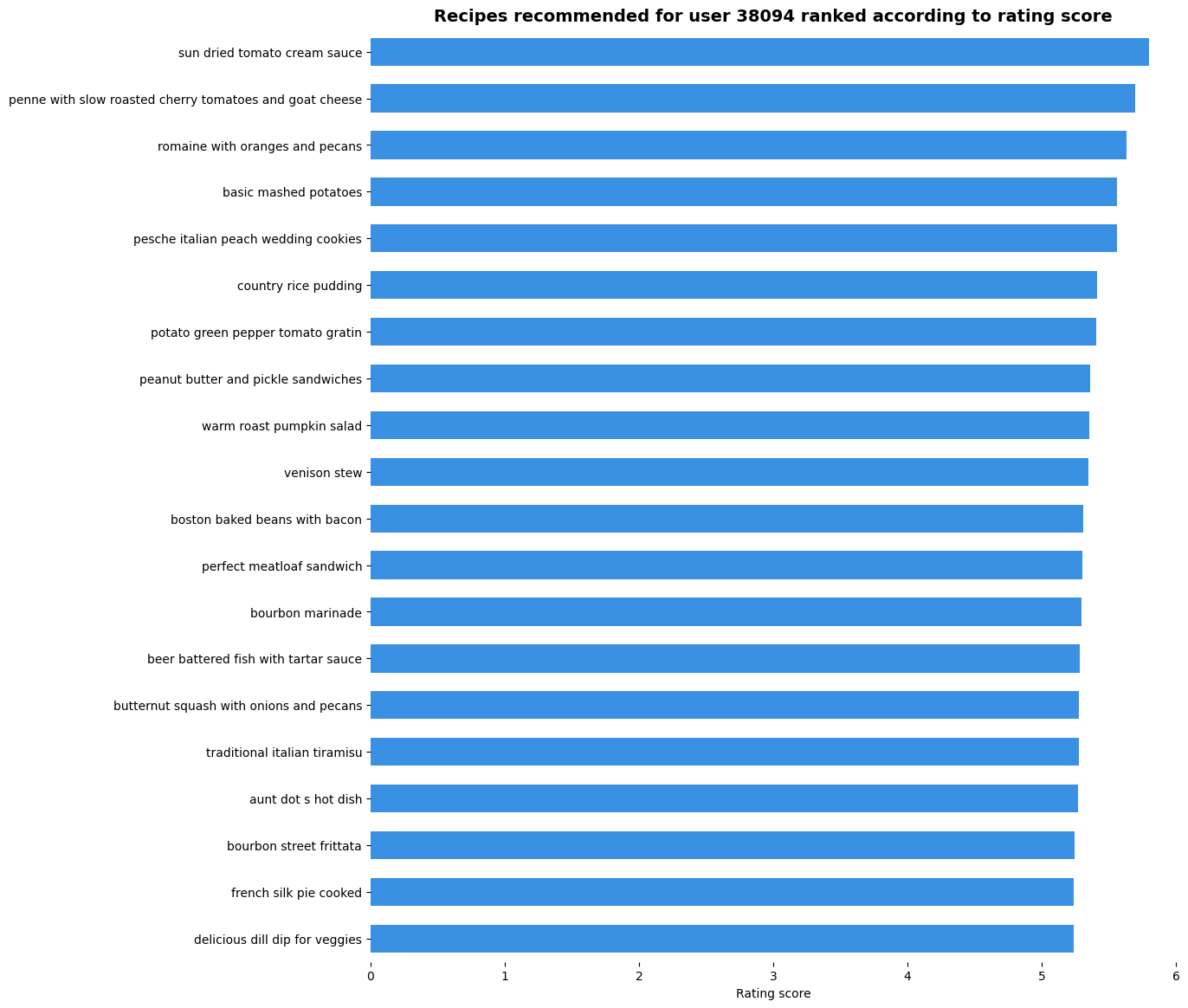
We can now extract the first top k ranked items and annotate the recipe IDs with recipe name and description. We will extract the first 20 items and annotate them.