This analysis presents an approach to perform automatic knowledge extraction from scientific articles using natural language processing followed by Latent Dirichlet Allocation-based topic modeling.
Introduction
In this analysis we will perform automatic knowledge extraction from scientific articles using natural language processing followed by topic modeling. To conduct this analysis, we will download abstracts from scientific life science articles via Pubmed, process them with an NLP-pipeline to perform biomedical named entity recognition and finally we will create a topic model using Latent Dirichlet Allocation (LDA).
Pubmed Downloading
code
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsimport spacyimport en_core_web_mdfrom spacy import displacy# Visualise inside Jupyter notebookimport pyLDAvis.gensim_modelspyLDAvis.enable_notebook()from bertopic import BERTopicfrom Bio import Entrezfrom bs4 import BeautifulSoupfrom gensim.corpora.dictionary import Dictionaryfrom gensim.models import LdaMulticorefrom gensim.models import CoherenceModelfrom wordcloud import WordCloud# Disable deprecation warningsimport warningswarnings.filterwarnings("ignore") %matplotlib inline
The focus of this analysis is on extracting knowledge about Caspase-2. This protein may function in stress-induced cell death pathways, cell cycle maintenance, and the suppression of tumorigenesis. Increased expression of this gene may play a role in neurodegenerative disorders including Alzheimer’s disease, Huntington’s disease and temporal lobe epilepsy.
So a query to retrieve all Pubmed articles about Caspase 2 can be constructed as follows:
code
query ='"Caspase-2"[TIAB] or "Caspase-2"[TIAB] or "casp2"[TIAB]'results = search_pubmed(query)id_list = results['IdList']papers = fetch_details(id_list)
In the above query TIAB is a wilcard that signifies limit to title or abstract.
Data preprocessing
After all abstracts have been retrieved, we will need to perform some further processing to extract title, publication date, journal and the actual abstract text.
Because those fields of interest are nested in multi-dimensional dictionaries with missing keys, we will use some defensive programming to extract the relevant fields.
After we have processed all downloaded articles, relevant data fields are added to a data frame to facilitate further analysis.
code
articles_df.head()
title
abstract
year
journal
0
Old, new and emerging functions of caspases.
Caspases are proteases with a well-defined rol...
2014
Cell death and differentiation
1
ER Stress Drives Lipogenesis and Steatohepatit...
Nonalcoholic fatty liver disease (NAFLD) progr...
2018
Cell
2
PIDDosome-SCAP crosstalk controls high-fructos...
Sterol deficiency triggers SCAP-mediated SREBP...
2022
Cell metabolism
3
Caspase-2 mRNA levels are not elevated in mild...
Caspase-2 is a member of the caspase family th...
2022
PloS one
4
Characterization of caspase-2 inhibitors based...
Since the discovery of the caspase-2 (Casp2)-m...
2022
Archiv der Pharmazie
Data visualization
Now that the data set is in a tabular format, it is easy to visualize the data. For instance, to inspect whether the retrieved articles effectively are about Caspase-2, we can easily create a word cloud to get a first impression of the most frequently used words in the retrieved abstracts. The word cloud shows that the most frequently used word indeed is “caspase”. Other frequent words, such as “cell death” and “appptosis” are known functions associated with Caspase-2, further confirming that the correct Caspase-2 abstracts were retrieved.
Furthermore, we can visualize the number of published Caspase-2 papers per year easily as well.
code
fig, ax = plt.subplots(figsize=(12,5))plt.subplot(1, 2, 1)fig = articles_df['year'].value_counts().sort_index(ascending=True).plot.bar()fig.set_xlabel('Year')fig.set_ylabel("Number of Caspase-2 papers")fig.set_title("Number of Caspase-2 papers per year");plt.subplot(1, 2, 2)counts_df = pd.DataFrame(articles_df['year'].value_counts().sort_values()).astype('float64')fig = sns.regplot(x=counts_df.index.astype('int'), y="year", data=counts_df, order=2)fig.set_xlabel('Year')fig.set_ylabel("Number of Caspase-2 papers")fig.set_ylim((0,50))fig.set_title("Publishing trend for Caspase-2 papers");
The fitted trend line in the right graph seems to suggest that interest in Caspase-2 peaked around 2013-2014 and is declining since then.
Natural language processing (NLP)
Biomedical Named Entity Recognition
Because articles from Pubmed contain a distinct, scientific vocabulary with specific gene names, disease terms and other biomedical terms with a specific nomenclature, we will perform natural language processing (NLP) of the abstracts using the ScispaCy pipeline provided by the Allen AI institute. ScispaCy is a Python package containing spaCy models tailored for processing biomedical, scientific or clinical text.
In particular, the ScispaCy NLP pipeline contains a custom tokenizer that adds tokenization rules on top of spaCy’s rule-based tokenizer, a POS tagger and syntactic parser trained on biomedical data and an entity span detection model. Additionally, there are also NER models for more specific tasks.
To assess whether the ScispaCy pipeline works correct, we will quickly apply the named entity recognition pipeline to the first article and inspect the results. After visualizing the result, we can observe that all biomedical entitties and terms in the abstract are nicely annotated and highlighted.
Caspases
ENTITY
are
proteases
ENTITY
with a well-defined role in
apoptosis
ENTITY
. However, increasing
evidence
ENTITY
indicates multiple
functions
ENTITY
of
caspases
ENTITY
outside
apoptosis
ENTITY
.
Caspase-1
ENTITY
and
caspase-11
ENTITY
have roles in
inflammation
ENTITY
and mediating
inflammatory cell death
ENTITY
by
pyroptosis
ENTITY
. Similarly,
caspase-8
ENTITY
has dual role in
cell death
ENTITY
, mediating both
receptor-mediated apoptosis
ENTITY
and in its
absence
ENTITY
,
necroptosis
ENTITY
.
Caspase-8
ENTITY
also
functions
ENTITY
in
maintenance
ENTITY
and
homeostasis
ENTITY
of the
adult
ENTITY
T-cell population
ENTITY
.
Caspase-3
ENTITY
has important roles in
tissue differentiation
ENTITY
,
regeneration
ENTITY
and
neural development
ENTITY
in ways that are distinct and do not involve any
apoptotic activity
ENTITY
. Several other
caspases
ENTITY
have demonstrated
anti-tumor roles
ENTITY
. Notable among them are
caspase-2
ENTITY
,
-8
ENTITY
and
-14
ENTITY
. However,
increased
ENTITY
caspase-2
ENTITY
and
-8
ENTITY
expression
ENTITY
in certain types of
tumor
ENTITY
has also been linked to promoting
tumorigenesis
ENTITY
.
Increased
ENTITY
levels
ENTITY
of
caspase-3
ENTITY
in
tumor cells
ENTITY
causes
apoptosis
ENTITY
and
secretion
ENTITY
of
paracrine factors
ENTITY
that promotes
compensatory proliferation
ENTITY
in surrounding
normal tissues
ENTITY
,
tumor cell repopulation
ENTITY
and presents a
barrier
ENTITY
for
effective
ENTITY
therapeutic strategies
ENTITY
. Besides this
caspase-2
ENTITY
has emerged as a unique
caspase
ENTITY
with potential roles in maintaining
genomic stability
ENTITY
,
metabolism
ENTITY
,
autophagy
ENTITY
and
aging
ENTITY
. The present
review
ENTITY
focuses on some of these less studied and emerging
functions
ENTITY
of
mammalian
ENTITY
caspases.
Token Extraction
To further clean the text and extract meaningful tokens that will be used for further topic modeling, we will remove various fequent, less informative word categories based on their tags. These common words include categories such as adverbs, pronouns, punctuation, spaces, symbols, etc. Besides those common words, we will also remove stop words.
code
remove= ['ADV','PRON','CCONJ','PUNCT','PART','DET','ADP','SPACE', 'NUM', 'SYM']tokens = []for results in nlp.pipe(articles_df['abstract'], n_process=4): tok = [token.lemma_.lower() for token in results if token.pos_ notin remove andnot token.is_stop and token.is_alpha] tokens.append(tok)
After we have processed and cleaned the data, we canobserve that the extracted tokens all seem to be related to biomedical concepts. We will further modeled and refine those semantic concepts using topic modeling.
Topic modeling using Latent Dirichlet Allocation (LDA)
Latent Dirichlet Allocation
One commonly used algorithm for topic modeling is Latent Dirichlet Allocation (LDA) [Blei et al, 2003]. LDA is a topic modeling algorithm that is commonly used for discovering the underlying topics in a corpus in an unsupervised manner by using a generative probabilistic model of that corpus. One underlying assumption that the model makes, is that words and documents are exchangable. So word order is not taken into account by the model. This assumption is also known as the “bag-of-words” model.
Essentially, every document is a mixture of topics and ach topic is a distribution over terms in a fixed vocabulary. A document can then be generated by sampling the topics from each document and then sampling words from each sampled topic.
More formally, if:
\(K\) = the number of topics:
\(M\) = is the size of the word corpus
\(N\) = is the number of documents
\(Z\) = is a specific topic
\(W\) = is a specific word
then the LDA model can be defined by the following formula:
\(\displaystyle P({\boldsymbol {W}},{\boldsymbol {Z}},{\boldsymbol {\theta }},{\boldsymbol {\varphi }}, \alpha ,\beta )\) is the joint probability to generate a document can be computed using the following formula
\(\prod _{i=1}^{K}P(\varphi _{i};\beta )\) is the Dirichlet distribution of topics over terms
\(\prod _{j=1}^{M}P(\theta _{j};\alpha )\) is the Dirichlet distribution of documents over topics
\(\prod _{t=1}^{N}P(Z_{j,t}\mid \theta _{j})P(W_{j,t}\mid \varphi _{Z_{j,t}})\) is the probability of a word given a topic
Bag-of-words model
To create a corpus, we will transform the tokenized abstracts into a simple dictionary. Subsequently the dictionary is filtered to exclude words with extreme frequencies, i.e. words with less than 3 occurences in documents and words that occur in more than 50% of documents. After filtering, we will convert the dictionary into a bag-of-words model that will be used as a corpus for the LDA model.
code
token_dict = Dictionary(articles_df['tokens'])token_dict.filter_extremes(no_below=3, no_above=0.5, keep_n=500)corpus = [token_dict.doc2bow(doc) for doc in articles_df['tokens']]
Topic coherence
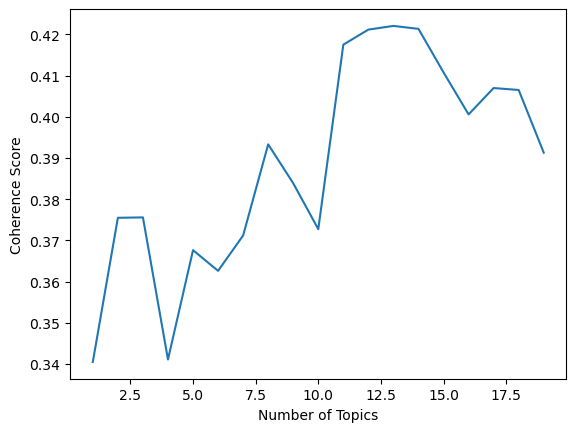
LDA assumes a fixed number of topic, so one hyperparameter that needs to be optimized is the number of topics. To determine the optimal number of topics, the topic coherence score can be computed for various topic models with a differing number of topics. Essentially, the coherence socre for a single topic measures the degree of semantic similarity between high scoring words in that topic. The LDA model which has the highest coherence overall score then can be considered the best LDA model with the optimal number of topics.
To compute the topic coherence score, we will use Gensim’s CoeherenceModel class, which implements a four-stage topic coherence pipeline as described in [Roder et al, 2015].
Basically, the pipeline comprises the following steps:
Once the optimal number of topics has been defined (in this case 9), we can compute the final topic model by setting the function argument num_topics=9.
We can then visualize the final model using the pyLDAvis package. The pyLDAvis package generates an interactive visualization to explore the different topic classes and the constituent terms that define a specific topic. Within a selected topic we can lookup the stimated term frequency for the term within the selected topic, as well as the overall frequency of that term in the corpus.
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. Journal of machine Learning research, 3(Jan), 993-1022.
Röder, M., Both, A., & Hinneburg, A. (2015, February). Exploring the space of topic coherence measures. In Proceedings of the eighth ACM international conference on Web search and data mining (pp. 399-408).